May 22, 2025
In September 2022, Cabify marked the end of an era by announcing a major shift: transitioning from deploying our services with an in-house CI/CD tool to embracing GitOps with ArgoCD*.
In essence, this move meant:

Setup Overview:
And as it always is, in the beginning, ArgoCD ran flawlessly: it was fast, efficient, required minimal resources, and developers were highly satisfied but after two years and exponential growth in applications and clusters, teams began raising issues and questions about ArgoCD’s performance in our Kubernetes Testing Environments (KTEs)**.
Here’s the story of how we enhanced our ArgoCD performance by 100x and shared those improvements with the community
ℹ️
If you want to learn more about the journey we’ve taken to implement ArgoCD at Cabify, and KTEs check out the post “Scaling ArgoCD to 50+ Testing Environments.”
Let me introduce you to who we are 😎!
We are the Developer Experience (DevX) Team at Cabify, a part of our Engineering organization dedicated to making life easier for developers. We’re here to streamline workflows, create tools, and optimize environments so our developers can focus on building amazing products for our users. In essence,
“We build products for those who build the product”
and yes! deployment is a fundamental part of our responsibilities.
At the beginning of 2024, it became increasingly common to encounter issues related to the performance of ArgoCD, particularly concerning application changes not being reflected in the target cluster.
This type of problem was twofold:
DevX was spent resolving these types of incidents rather than progressing on other initiatives.To understand better the problem, let me describe briefly the ArgoCD architecture and focus on the components related:

Indeed, the logs from the Repo Server confirmed that certain operations, such as GenerateManifest, GetRevisionMetadata, and GetGitDirectories, experienced spikes at times, reaching durations of 15 to 50 minutes:
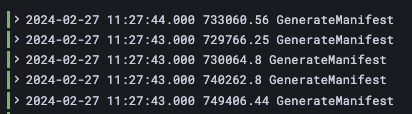
The issue described impacts both the Repo Server and the CMP plugin, which is why they were highlighted above 😏
Digging a little bit using pprof:
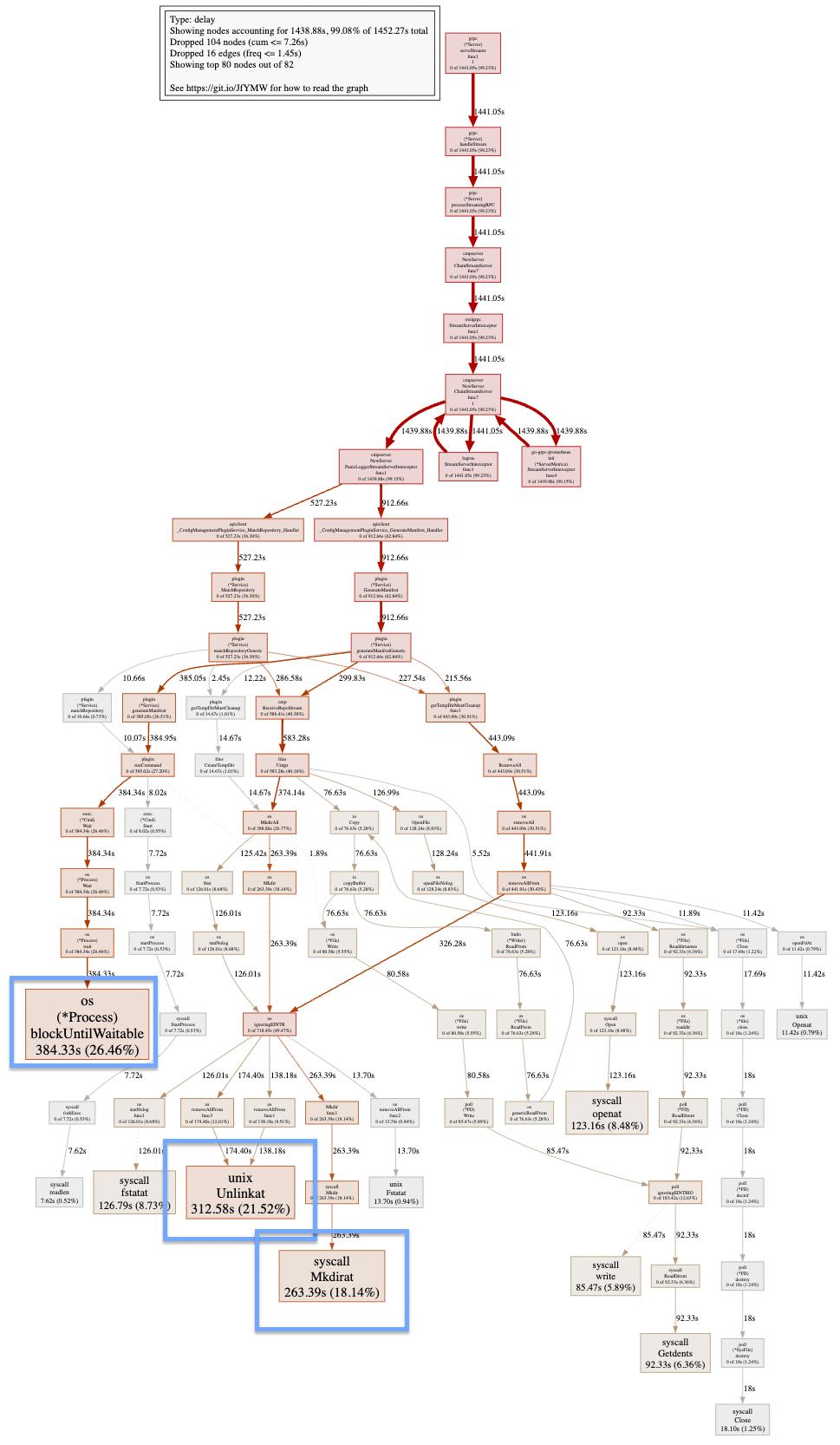
We noticed that most of the time, the Repo Server is just waiting ⌛!
Upon reviewing the CMP plugin code, we gained a clearer understanding of its functionality and identified areas that may be influencing the current issue:
Most of the time is spent waiting for the creation and deletion of directories and files (blockUntilWaitable).
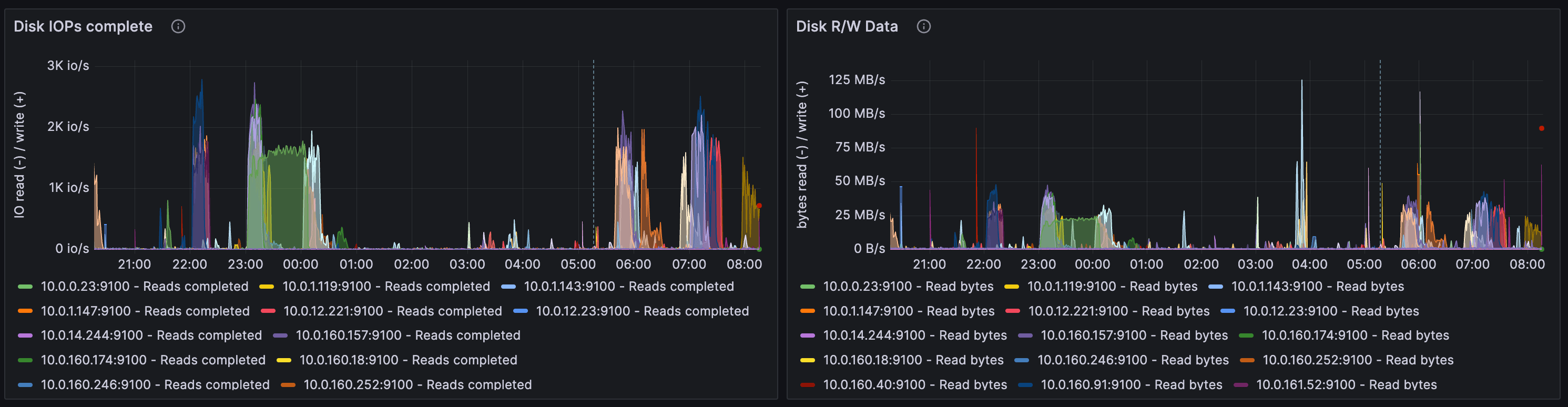
We were able to confirm the enormous spikes in disk write operations and this situation worsens if multiple Repo Servers are deployed on the same node:
When we talk about variable interpolation, we refer to the need to define an application in a single manifest that can be deployed across multiple ephemeral KTE clusters. These variables may include environment variables, ingress hosts, and more. Eg:
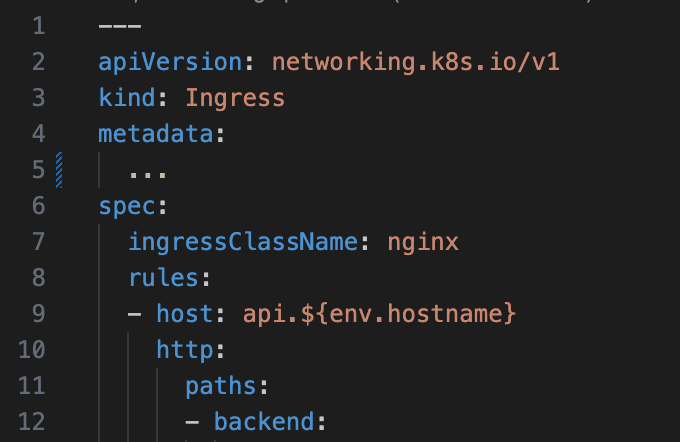
It is common for such an application to require environment-specific variables. That’s why we use the CMP plugin, which allows us to perform this variable interpolation during the generate command.
Given our need for variable interpolation, we initially considered offloading this responsibility from ArgoCD by using admission mutating webhooks. However, this approach has significant drawbacks, particularly when working with server-side apply:
IgnoreDifferences and ManagedFields, do not function as intended in this context and cause an eternal reconciliation loop.ManagedFields is discouraged 💀ManagedFields has limitations; it cannot designate an element within a list as the manager, resulting in entire lists being marked, leading to the loss of synchronization for significant blocks of manifests (such as host in ingresses).IgnoreDifferences also fails to work for elements within a key, such as in ConfigMap / CRDsArgoCD didn’t offer much beyond exclusion features, and we were not the only ones experiencing performance issues with similar configurations:
At this point, we start asking, how far-fetched is it to propose this change to the community and actually implement it? Let’s do it 💪!!
By examining the code of the Repo Server and cmp-plugin in detail, we identified two potential quick wins that could significantly improve the performance of ArgoCD:
We noticed that to check if Discovery was enabled, the Repo Server, per application, would internally compress the entire repository and send it to perform the matchRepositoryCMP. In monorepo scenarios with hundreds of applications, or even worse, in situations where a single node could host multiple Repo Servers, this could place unnecessary stress on the disk.
Our proposal was to extend the API provided by the cmp-plugin with a new operation, CheckPluginConfiguration, which allows for a quick and efficient way to determine if the plugin has Discovery configured.
Take a look at the contribution for more info.
ArgoCD has already defined the manifest-generate-paths annotation, which uses the paths specified in the annotation to compare the last cached revision with the latest commit and trigger reconciliation.
The proposal aimed to simplify the number of resources transmitted from the Repo Server to the CMP plugin by taking this annotation into account. This would allow, in monorepo scenarios, for a limited set of resources to be compressed and sent to the plugin instead of sending the entire repository, which in our case could consist of thousands of resources.
Take a look at the contribution for more info.
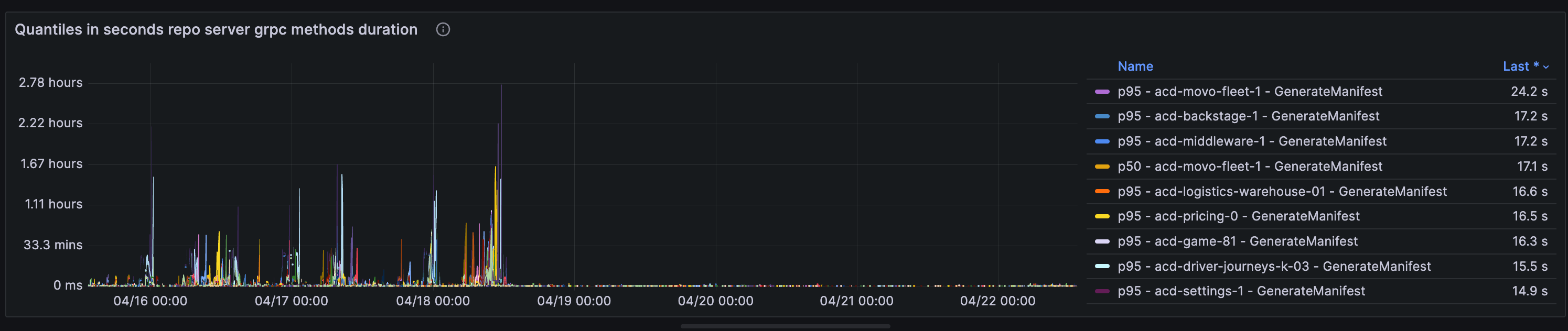
After applying the changes in our environments, we observed a significant reduction in the times for the GenerateManifest operations, returning to a matter of seconds as we have in production environments:
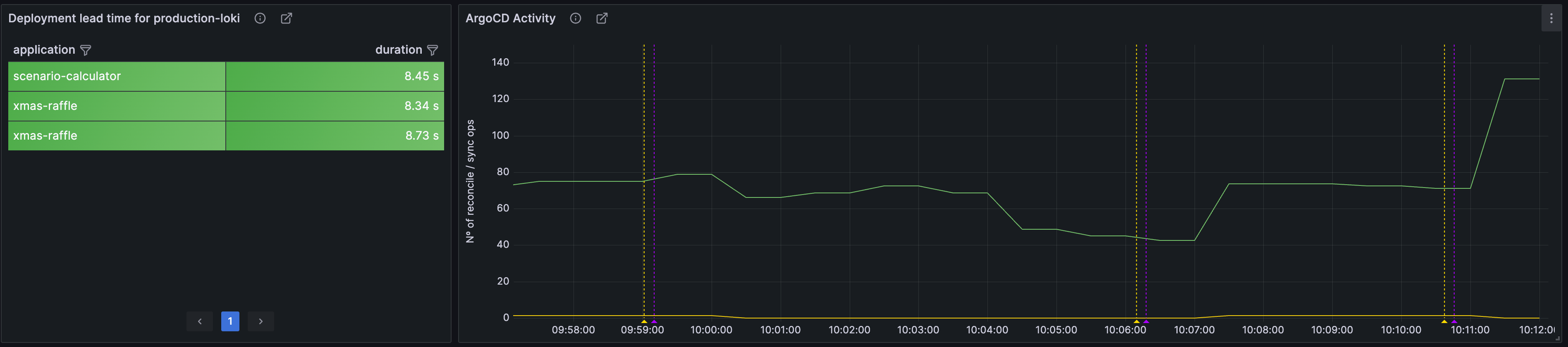
..and that’s all folks 🚀🚀!
Do you like what you read? It’s easy, join us and be part of the journey 👋!

Software Engineer