Apr 09, 2026

Our lists loaded. Queries returned. Yet complex filters felt slow, DB load was high, and adding “one more” search field was risky. This was the hidden cost of doing search with a transactional database. It worked, until growth turned “okay” into friction.
As a ride-hailing company, we’ve expanded beyond passenger transportation into delivery and logistics services. Our Delivery Management System (DMS) handles the end-to-end lifecycle of parcels that clients send through our platform. From pickup requests to final delivery, the DMS tracks every parcel’s route, status, and metadata.
This expansion brought new operational complexity. Operations teams, customer support, and drivers all need to search, filter, and manage parcels efficiently across multiple dimensions: status, location, time windows, client details, and more.
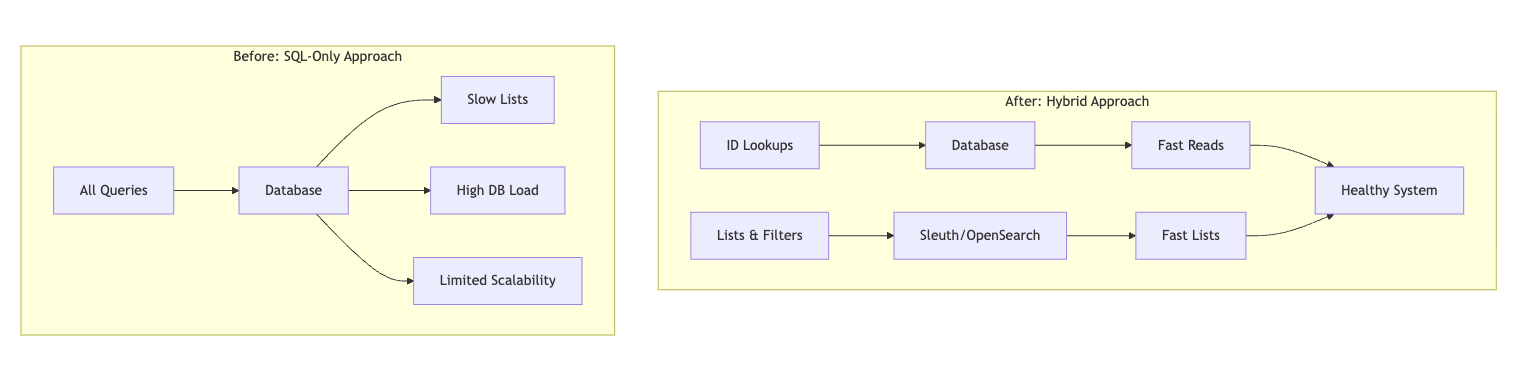
We started with direct SQL in the DMS: a simple SearchCriteria built queries against the DB. With few parcels, it was fine. Growth changed the shape of the problem.
The database had grown to over 20 million rows and was handling hundreds of queries per second. At this scale:
We needed list views that stayed fast at scale without pushing the transactional DB over the edge.
The challenge was clear, but the solution needed to meet specific criteria. We needed something that was simple to use for our engineering teams, delivered fast search performance even under heavy load, and could scale as our parcel volumes continued to grow.
Why a dedicated search engine? Traditional relational databases are optimized for transactional consistency and point queries, not for the kind of exploratory, multi-dimensional filtering our users needed. OpenSearch is a distributed search and analytics engine built specifically for handling large-scale data with complex query requirements. It excels at:
We already had Sleuth, an in-house tool that abstracts OpenSearch complexity and provides a consistent interface for teams. The task was to apply Sleuth to our DMS search problem while ensuring:
Sleuth packages OpenSearch’s complexity in a manageable, consistent way for teams:
It’s not a shortcut; it’s a repeatable way to operate search at product scale.
Our model is mixed by design:
Indexing is event-driven. When a parcel changes, the relevant fields reach Sleuth. Sleuth applies the configured mapping and bulk-indexes into OpenSearch. Versioning ensures only the latest state is searchable. Net effect: very fresh search data optimized for filtering and sorting.
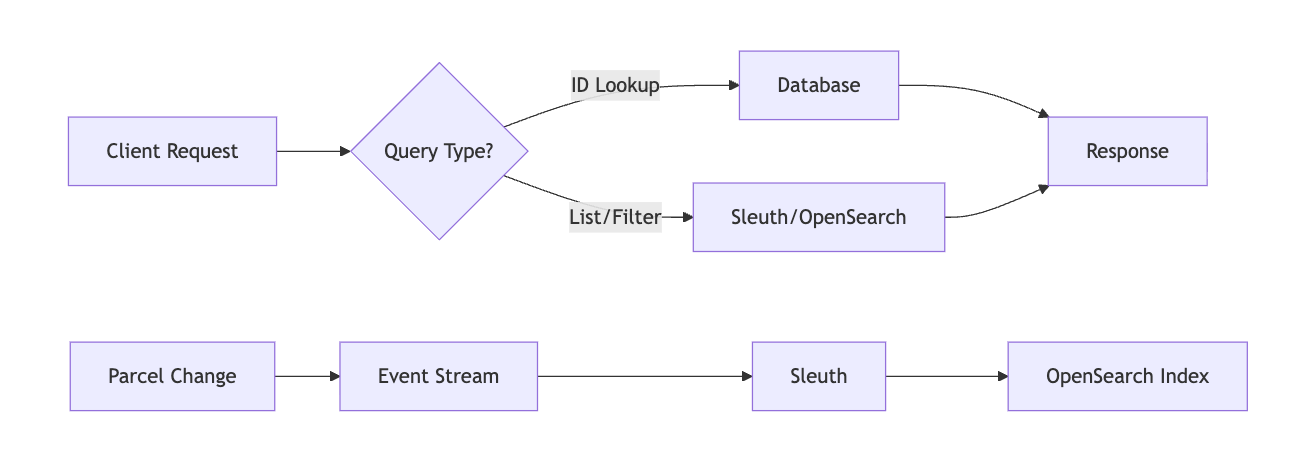
The improvements were immediate and measurable. Complex list queries that previously took seconds now return consistent millisecond responses, regardless of filter complexity. Database load dropped significantly as we moved exploration and search operations away from the transactional path, allowing the DB to focus on what it does best: maintaining data integrity and handling point queries.
Product iteration became simpler. Teams can now add fields and filters in a standardized way rather than writing per-service ad-hoc code. This means:
Most importantly, the user experience improved at scale. Lists load fast, sorting is responsive, and latency is predictable, even as data volumes grow.
Of course, this approach comes with trade-offs. OpenSearch is not the source of truth. A small indexing delay exists between database changes and search visibility. In practice, this delay is negligible for most use cases, but it’s something to be aware of when designing features that require immediate consistency.
The standardization that makes Sleuth powerful also means scoped flexibility. Some advanced search features may need special handling outside the standard patterns. We’ve found this to be a reasonable constraint that encourages thoughtful design rather than ad-hoc solutions.
There’s also an adoption curve. Teams need to learn about:
However, once teams climb that curve, they benefit from a shared, solid foundation that accelerates future development.
This approach fits particularly well when your service relies on lists with multiple filters and sorts over large volumes of data. If users are constantly exploring data through different combinations of filters, dates, and search terms, a dedicated search infrastructure becomes essential.
It’s also ideal when you want to protect the transactional database from exploratory queries that could degrade response times. By offloading these workloads, the database can maintain consistent performance for critical transactional operations.
Finally, this makes sense when you aim to align teams around a common search model and observability. Instead of each team building their own search infrastructure with different patterns and monitoring, Sleuth provides:
This alignment reduces cognitive load and makes it easier for engineers to work across different parts of the system.
Real-time product search is a different workload from transactions. We treat it that way.
By matching each workload to the right tool, we achieved better performance, lower operational risk, and a foundation that scales with our product.

Software Engineer