Dec 03, 2025

Finding your driver in a busy airport can sometimes feel harder than catching your flight. At Cabify, we wanted to change that.
In 2022, we rethought how our app handles pickups at major transport centers: airports, train stations, and bus terminals. We call these places Hubs. They process thousands of daily interactions and represent one of our most critical user experiences.

The Hub experience is time critical because riders need to find their driver efficiently. In 2022, our app experience in Hubs was still underdeveloped and caused friction for riders and drivers.
Riders often face these problems at Hubs:
Before improvements, some airports in Argentina and Spain caused friction:
Our goal: Guide riders from their location to the pickup point. Make it easy to identify the driver and estimate walking time.
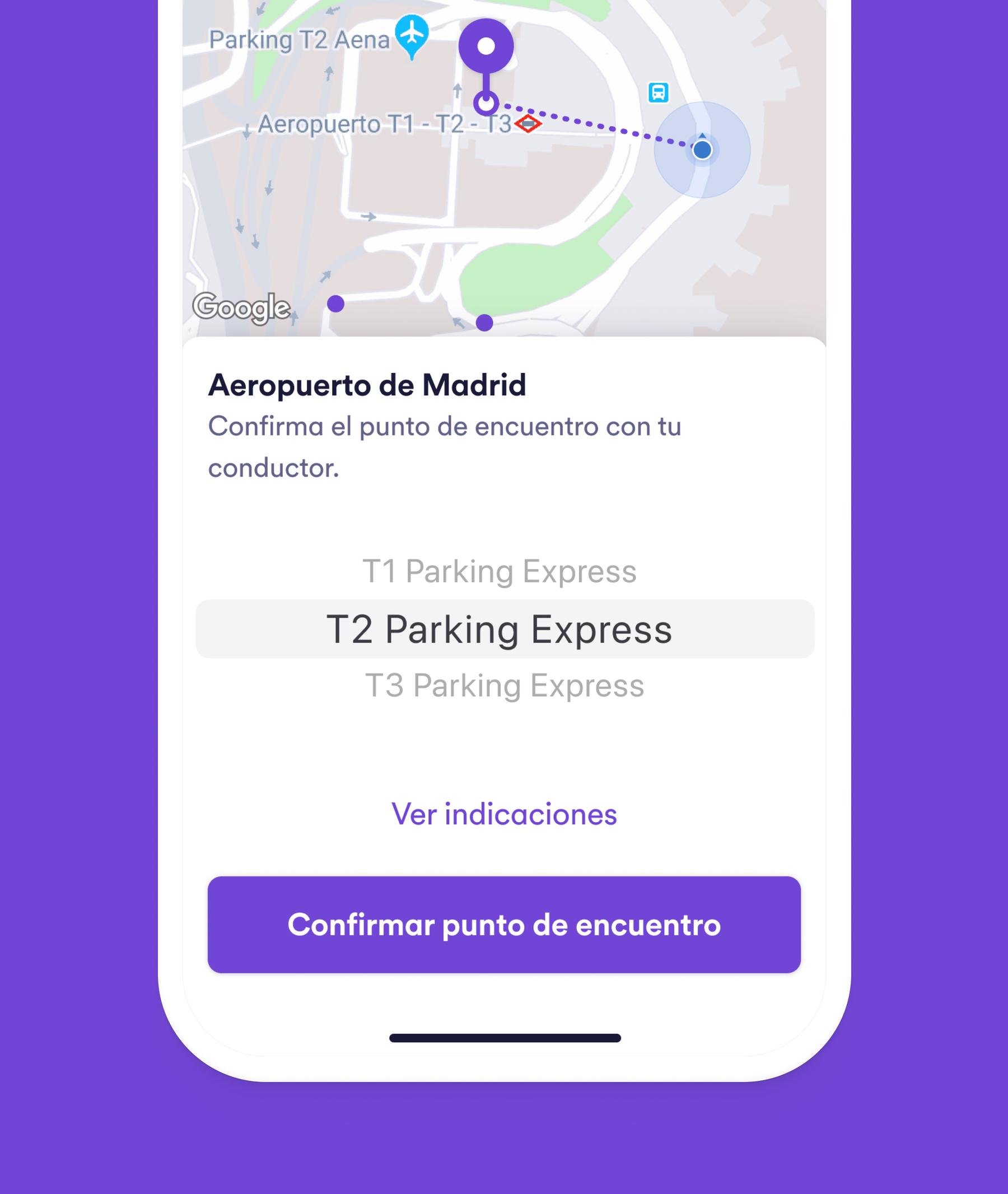
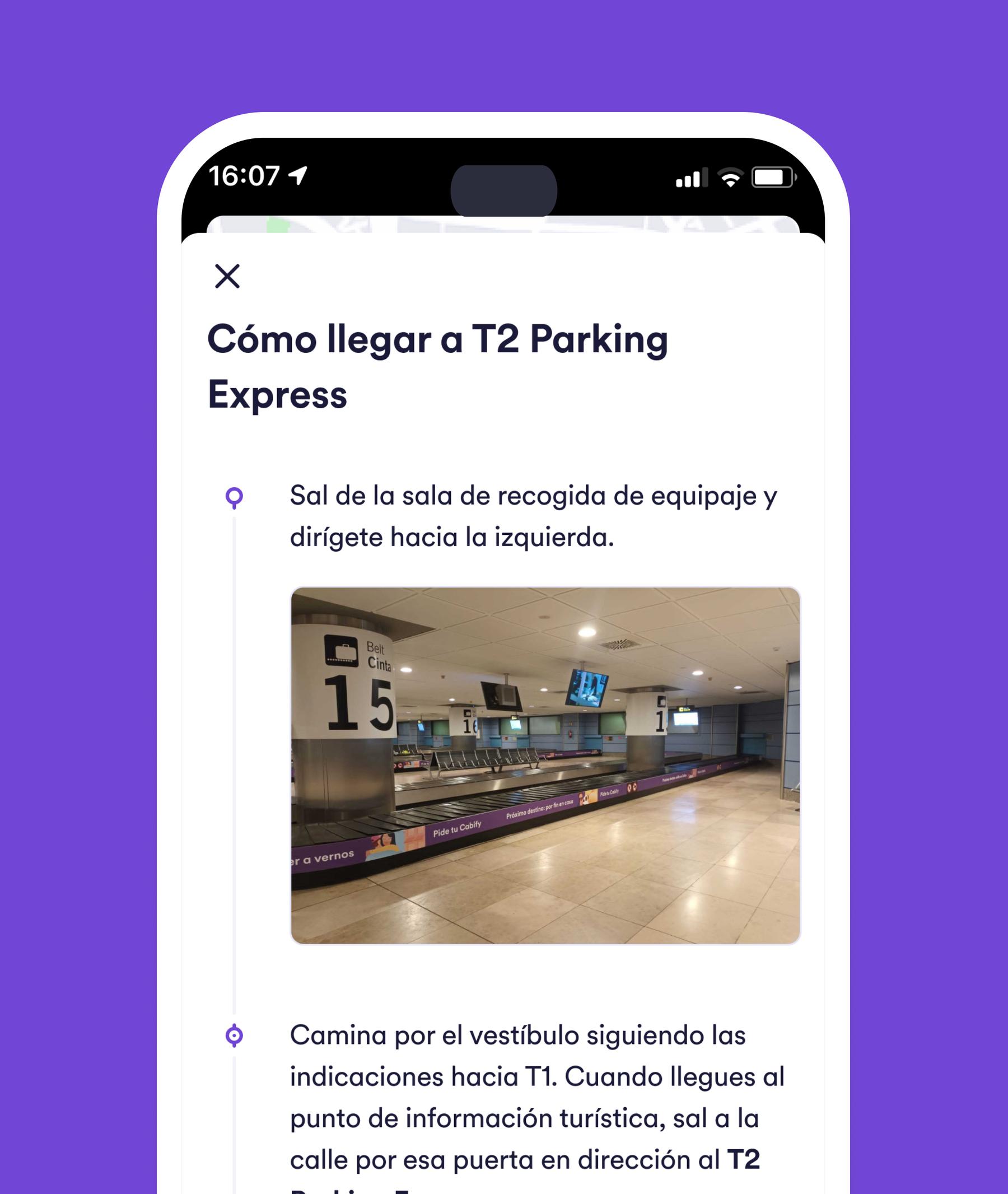
We deployed contextual instructions: step-by-step walking guidance and pickup point banners. Riders found drivers faster.
The tradeoff: Every Hub change required engineering work or hardcoded configurations, code deployment, etc. Updating instructions for a single Hub took days. With demand growing across multiple markets, this wouldn’t scale.
Riders initially saw instructions after requesting a journey. Moving this to the checkout phase (where users can see the list of available types of journeys) set expectations earlier and increased confidence. Result: 13% increase in successful journeys in the first month.
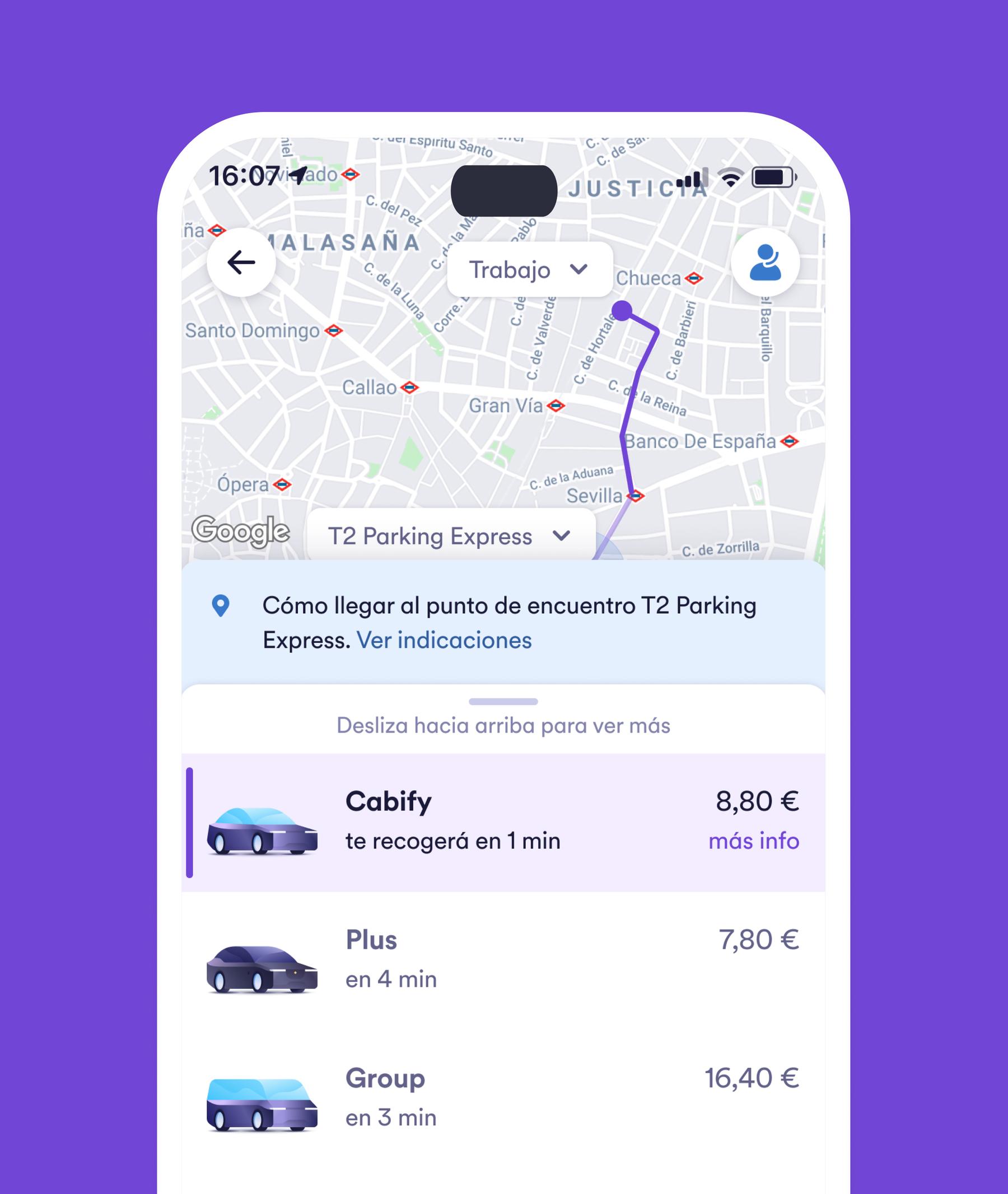
The improvement validated the approach. But demand increased faster than we could deploy: operations teams requested changes for 50+ Hubs across multiple markets. Event Hubs (concerts, fairs), new terminal pickup points, updated walking instructions, etc. Every request created 2-week engineering backlogs.
Phases 1 and 2 proved the value. They also exposed the constraint: engineering capacity couldn’t scale with market demand.
Rider Admin eliminated this by giving operations teams direct Hub management.
We chose Elixir and Phoenix LiveView for practical reasons. We needed a production-ready backoffice fast and this technology leveraged existing team knowledge and allowed us to work without handing over parts to our React specialists. This decision allowed for 2-week delivery with just 3 engineers: one backend, one iOS, and one Android. No React/SPA complexity. No JavaScript build pipelines. We used our existing Elixir expertise and got real-time validation without client-side code.
The architecture is simple. Phoenix LiveView UI talks to Rider Core API (REST) for persistence. It publishes audit events to MessageBus for compliance. Images upload directly to S3. Aker (our internal RBAC service based in Casbin) enforces permissions.
We used Ecto embedded schemas on the LiveView server for type safety and validation:
defmodule RiderAdmin.Hub do
use Ecto.Schema
import Ecto.Changeset
embedded_schema do
field(:uid, :string)
field(:location_id, :string)
field(:active, :boolean)
field(:start_date, :string)
field(:end_date, :string)
field(:timezone, :string)
embeds_many(:meeting_points, MeetingPoint)
embeds_one(:title, Locale, on_replace: :update)
end
def changeset(hub, params) do
hub
|> cast(params, @fields)
|> cast_embed(:meeting_points)
|> cast_embed(:title)
|> validate_required([:location_id])
end
end
For local development, WireMock mocks upstream services.
The platform enabled rapid feature delivery:
The infrastructure now powers Cabify Club, A/B Experiments, and other features. Product teams iterate without engineering involvement, reducing delivery time from weeks to hours. Building a reusable platform rather than a point solution multiplied value across product areas.
The system uses a BFF layer to orchestrate Hub data delivery. When a rider opens the app at a Hub, we detect their location (500m-2km boundary) and serve localized instructions through Rider Core.
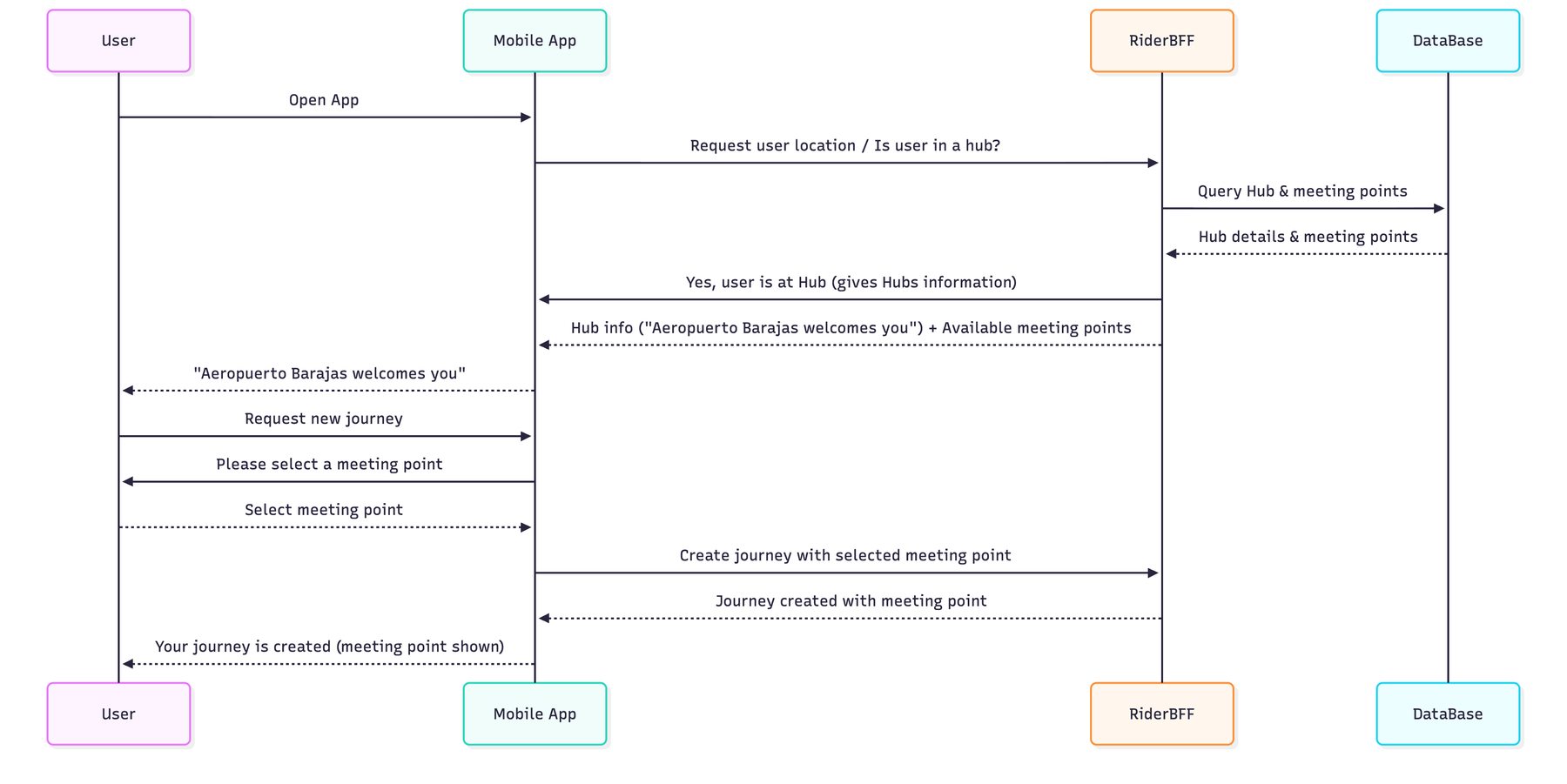
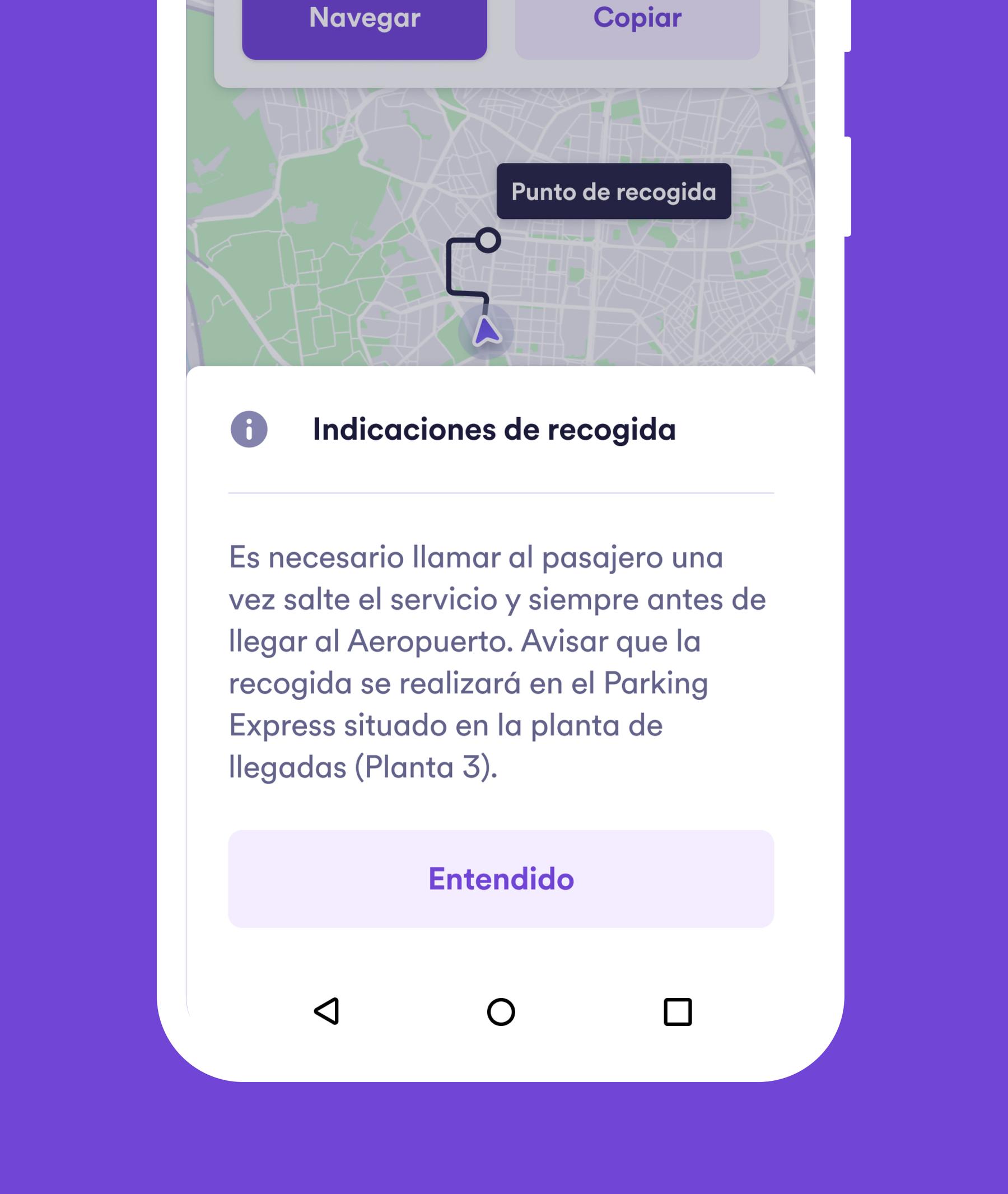
Real-time coordination is critical. Drivers get GPS coordinates for the meeting point, not the rider’s location. They receive turn-by-turn navigation for vehicle access. When drivers enter the Hub boundary (200m), riders get a push notification.
The system handles edge cases. GPS drift? It falls back to map selection. Hub unavailable? It suggests alternative pickup points. E2E tests simulate the full journey: GPS mocking, driver acceptance, and geofence notifications.
The results:
This speed proved transformative. Teams now deploy and adjust Hubs in hours instead of weeks. This is crucial for capturing revenue during high-demand events.
The Challenge: We needed to migrate 100+ production Hubs. These handled 300+ requests per minute. The migration went from single pickup points to multiple meeting points. We required zero downtime across all mobile client versions.
Our Approach:
We rebuilt the data model from scratch. We used normalized tables with separate foreign key relationships. Then we migrated all existing Hubs to the new schema. The critical innovation was progressive traffic shifting with feature flags using Flagr at the BFF layer:
defmodule RiderBFF.HubsController do
def get_hub(conn, %{"hub_id" => hub_id}) do
entity = build_flagr_entity(conn)
case Flagr.enabled_for_entity?(entity, "hubs_v2_migration") do
{:ok, true} ->
# Route to new V2 API
RiderCore.V2.Hubs.fetch_by_location_id(hub_id)
{:ok, false} ->
# Route to legacy V1 endpoint
LegacyHubsService.fetch(hub_id)
end
end
end
We rolled out progressively: 5% → 25% → 50% → 100% over 7 days, monitoring API latency, error rates by client version, and crash rates. Both V1 and V2 returned identical response structures, making the migration transparent to mobile apps regardless of version.
Results: Zero downtime, no error rate increase, immediate rollback capability via Flagr (never needed), and V1 deprecated 2 weeks post-migration.
Key Lessons: Separate tables avoided dual-write complexity. BFF-layer feature flags provided traffic control without polluting business logic. Response format consistency eliminated client-side migration handling.
User feedback showed riders needed visual guidance for each navigation step, not just a single header image. We extended the Instructions schema to support up to 6 images per step, integrated S3 direct uploads via LiveView, and implemented lazy loading with local caching on mobile to reduce data usage.
Hubs evolved from eliminating airport confusion into a production system handling thousands of concurrent pickups. The technical choices (Phoenix LiveView over React, Ecto embedded schemas for validation, progressive Flagr rollouts) reflect pragmatic tradeoffs under real constraints.
The 58% order increase validates the approach. More importantly, the self-service infrastructure now powers loyalty programs, experiments, and other product features. What started as rider instructions became a platform that eliminates engineering bottlenecks across the organization.

Senior Software Engineer