Oct 13, 2025

Upgrades are an inevitable part of databases lifecyle, and when they arrive, they often present a delicate situation. At Cabify, we currently manage over 180 RDS MySQL 8.0 instances (in addition to other types of databases). These instances did not always run on MySQL8; we transitioned from version 5.7, and in the future, they may evolve further.
Like many other companies, Cabify adheres to strict Service Level Objectives (SLOs). Even minor downtimes during migration can have a significant overall impact. Therefore, we must upgrade our databases with minimal downtime (spoiler alert: we do this without any downtime).
This article aims to explain how we achieve this and how we keep our database instances consistently updated without impacting the business.
NOTE: If you’re only interested in the technical details of how we upgrade without downtime, feel free to jump to this section.
Our infrastructure has been in constant evolution, and so have our databases. Back in 2020, all our infrastructure was running on GCP. There was no defined process for database upgrades or migrations, which meant we tried to avoid them as much as possible, accepting downtime when necessary. However, at that time a decision was made to migrate everything to AWS. The details of this migration deserve an article of their own. One of the critical points was: how can we migrate all our databases from one provider to another without downtime and without losing any data? No public tool performed this task easily back then. So we decided to design a new tool utilizing the functionalities of ProxySQL. Since then, this tool has been an integral part of our infrastructure team and has evolved to cover more use cases. Nowadays, we use it as the main tool for making MySQL upgrades without downtime.
To make correct decisions, it’s essential to evaluate the trade-offs, which cannot be done without proper context. Therefore, let’s begin by explaining our current scenario in detail.
At cabify we group all our services into Tier Levels (from 1 to 3), with Tier 1 being the most critical one:
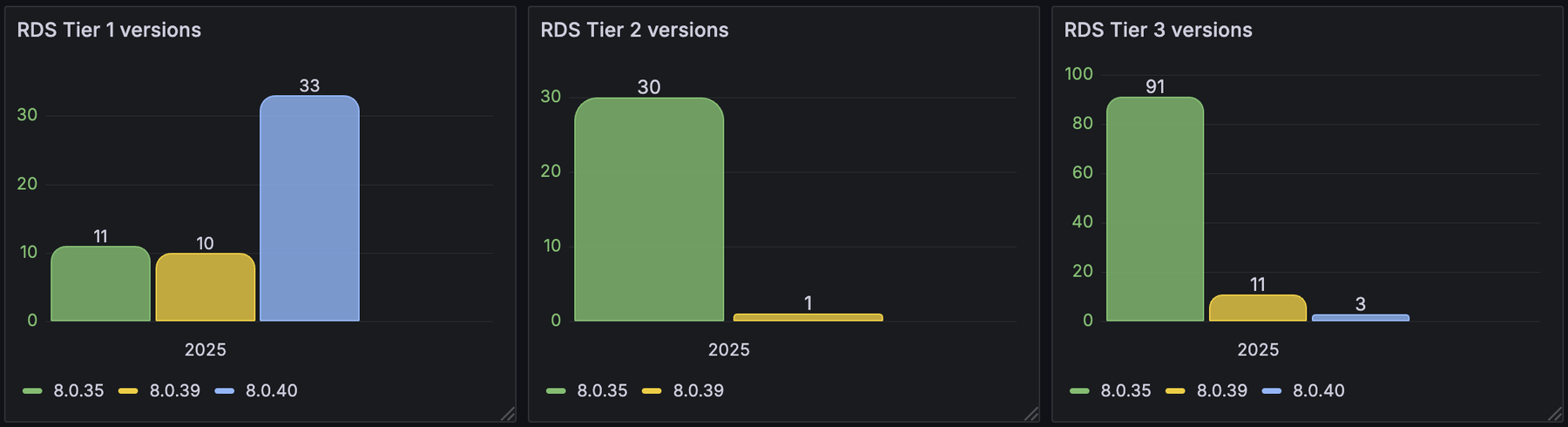
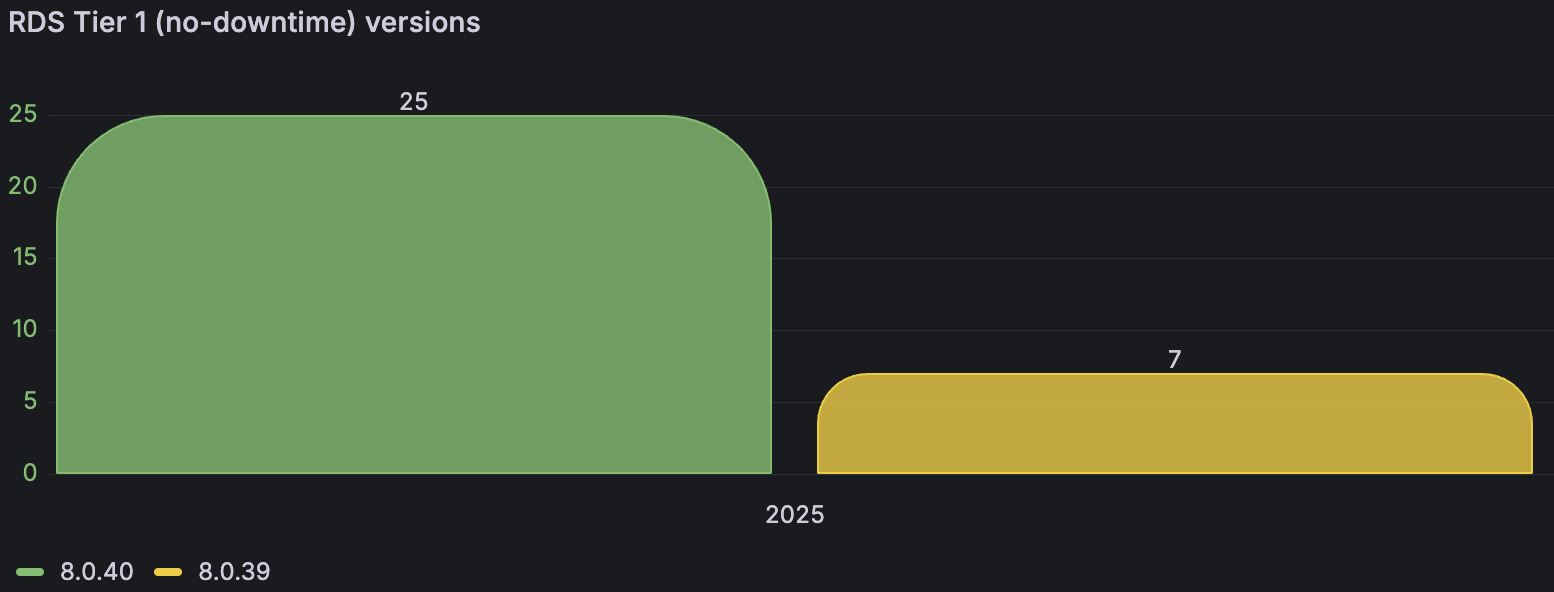
Databases are not an exception. These are the number of MySQL instances by tier and version:
Each tier level has its own SLOs, allowing some downtime. That classification drives some design decisions: for example, RDS MySQL8 instances in Tier 1 and Tier 2 are configured in Multi-AZ setup (secondary instance on another AZ ready to provide failover at all times), while Tier 3 instances are not. This allows us to provide a better SLI when a database instance fails, keeping our expenses controlled and focused where it matter most.
Certain Tier 1 instances that can tolerate downtime, typically because they are associated with business branches that only operate in specific regions, resulting in periods of minimal or no traffic.
Currently, we see that there are 32 instances that cannot afford downtime without impacting the core use cases of the company:
As we can see, the issue is not just a technical one; it also involves management. It is crucial to understand the impact of each database to mitigate risks. Therefore, at Cabify, we empower product teams with the responsibility of creating and managing their own databases, as no one knows better than they do how to tag and define the databases appropriately, always keeping the business perspective in mind.
Not all RDS instances have the same resource requirements. Some may demand more CPU, while others may require more disk space. Migrating an instance with 1TB of data is quite different from migrating one with just a few MBs. Even AWS-managed rollouts vary considerably based on these factors, see:
Automatic upgrades incur downtime. The length of the downtime depends on various factors, including the DB engine type and the size of the database.
It’s also important to note that having Multi-AZ enabled significantly affects the upgrade process. When Multi-AZ is enabled, the rollouts of minor versions follow this procedure (doc):
Downtime during the upgrade is limited to the duration it takes for one of the reader DB instances to become the new writer DB instance.
Let’s explore now the main reasons why we typically need to upgrade our MySQL8 instances. There are essentially four primary motivations:
gtid-mode.Some of our databases are configured with read-only replicas for various reasons (explaining when to use a read-only replica is beyond the scope of this article). This means that when an upgrade occurs, the resulting scenario will include the main instance along with all related read-only replicas, all configured with the new desired settings.
Another critical aspect that is often overlooked is vendor lock-in. In the past, Cabify successfully migrated all its infrastructure from GCP to AWS without downtime (main reason for start developing this MySQL migration tool). The future is uncertain, which is why it’s essential to avoid dependency on a single provider. While this topic could warrant a separate article, in summary, at Cabify we keep vendor lock-in with our providers as a risk in the decision making process, just like cost or availability. That allows us to ask questions like “how would we migrate all our MySQL instances out of AWS if necessary?” This solution mitigates that risk and provides us with the flexibility to chose a new provider if needed.
Now, let’s explore the strategies we can employ to upgrade our RDS MySQL8 instances.
This is a straightforward solution that works for us in most cases. It offers a significant benefit: there’s no manual work to do, as we allow AWS to handle the upgrade process, which translates to substantial savings in man-hours. Tier 3 instances are upgraded using this technique. Essentially, we wait for AWS to upgrade the instances when the version support end date has reached, accepting the associated downtime. The expected downtime here is a few minutes, depending largely on the instance size.
The same applies to Tier 1 instances, that can accept downtime and Tier 2 instances. However, keep in mind that these instances have Multi-AZ enabled, so downtime is reduced to the failover time, which should be less than one minute (usually around 30 seconds). This downtime could potentially be reduced to approximately one second by using RDS Proxy. However, this solution requires additional implementation to achieve that. Spoiler alert: this is similar to our current approach for achieving zero downtime.
This is another viable alternative. It is fast and easy to implement, but it comes with some clear drawbacks:
You can find an AWS migration guide here.
AWS offers a blue-green deployment strategy, which creates a staging environment that synchronizes with the main instance. Once the new staging instance is ready, you can promote it. However, this process is not atomic and does require some downtime (typically under a minute, although they were just few seconds in the demos we conducted).
As of the time of writing, Terraform support for this approach is far from perfect (terraform doc). For example, if the upgrade fails for any reason, it does not clean up the resulting mess. Additionally, it does not support the upgrade of instances with read replicas, which is relevant to some of our databases.
In conclusion, while this method appears to be a promising tool for the future, it is not the best option for us at this time. Also, keep in mind the issue of vendor lock-in.
Now, let’s delve into the interesting part: how we handle Tier 1 MySQL RDS instance upgrades/migrations without downtime and without vendor lock-in.
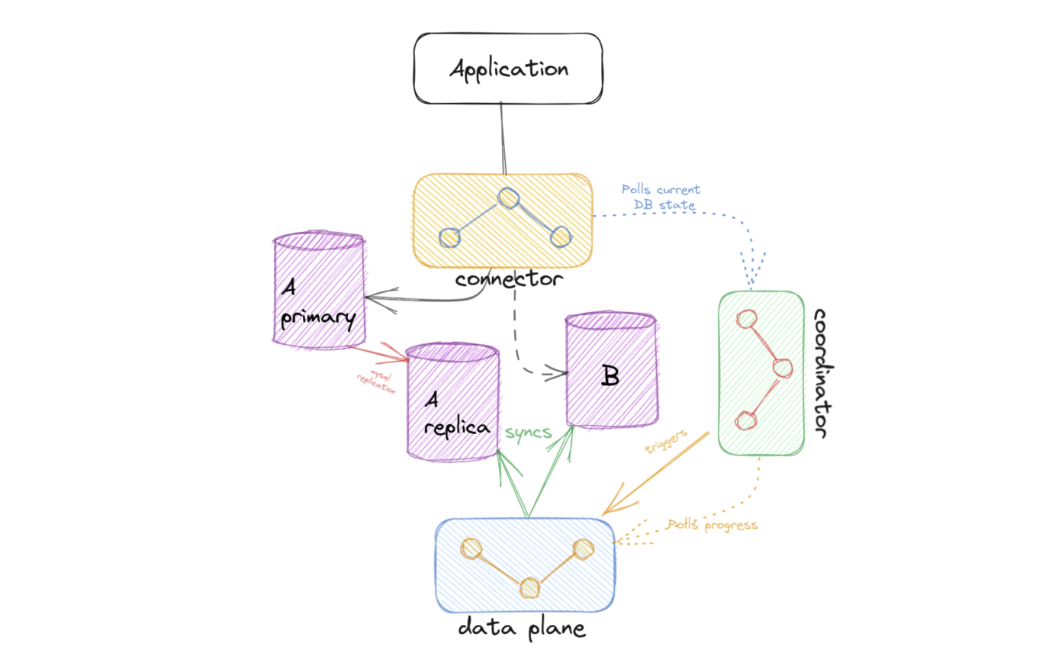
Consider the following general overview (don’t worry, we’ll dive into the details in the sections that follow):
The main components involved in our solution are:
mysqldump)We define two main steps in this approach:
The sync phase ensures that the new MySQL instance contains exactly the same data as the old one before we switch traffic over. This is critical for maintaining data consistency throughout the migration process. We have developed two distinct approaches to handle different database sizes and configurations:
Mysqldump Approach
This approach is suitable for smaller to medium-sized databases where the dump process can complete within a reasonable timeframe. The process works as follows:
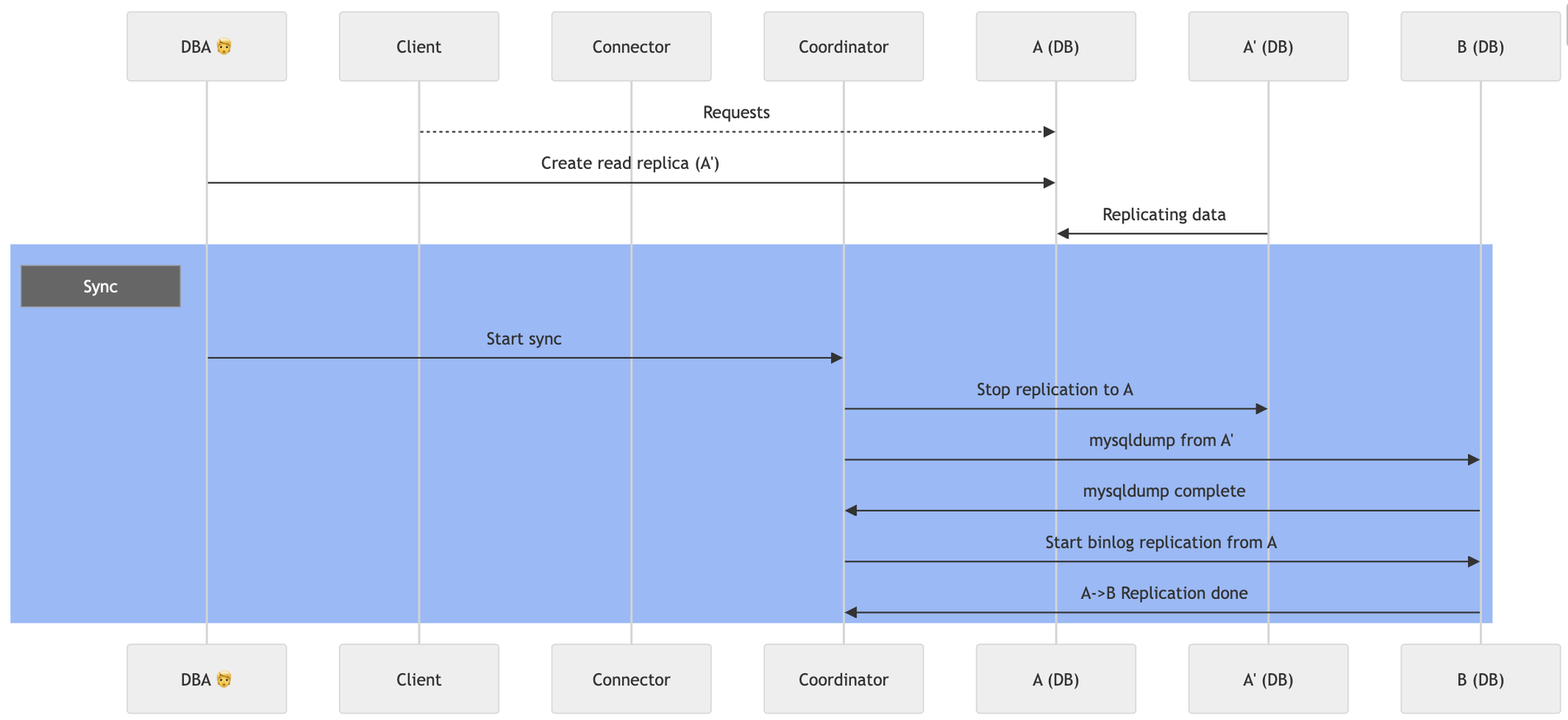
Create a Read Replica: We begin by creating a read replica from the old instance. This allows us to perform the data dump without impacting the performance of the production instance that continues serving live traffic.
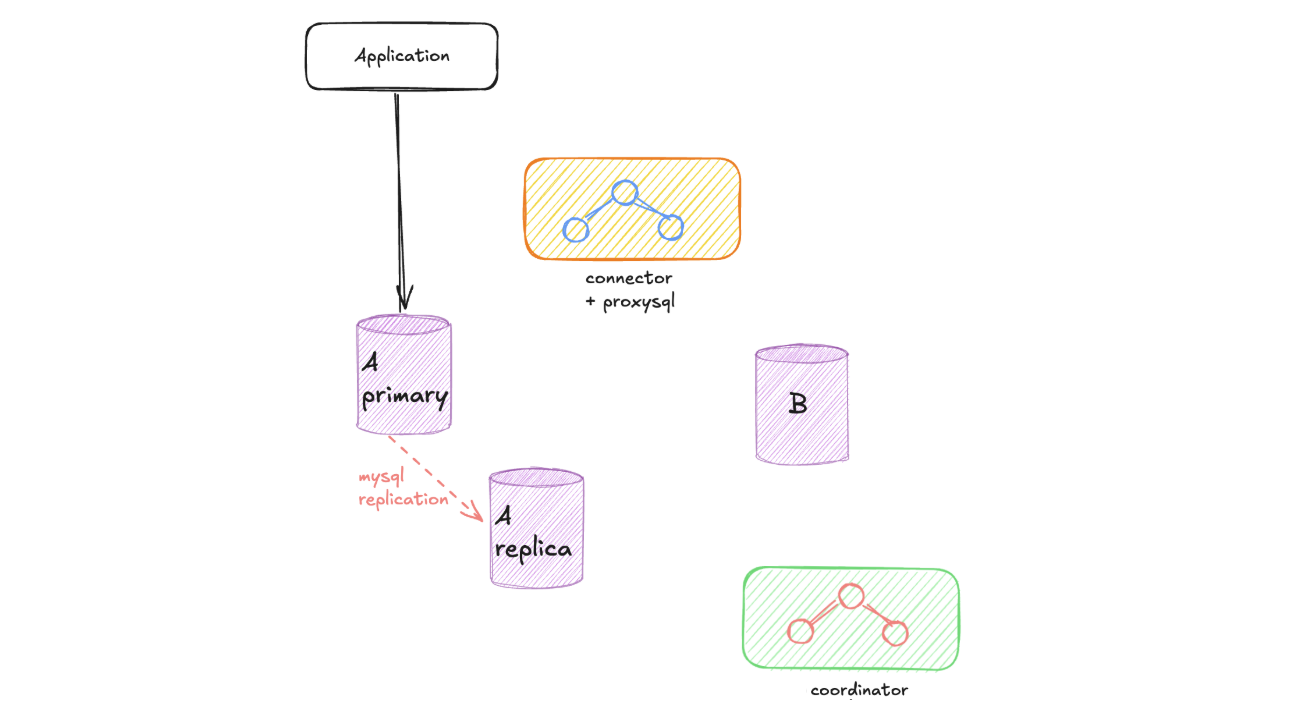
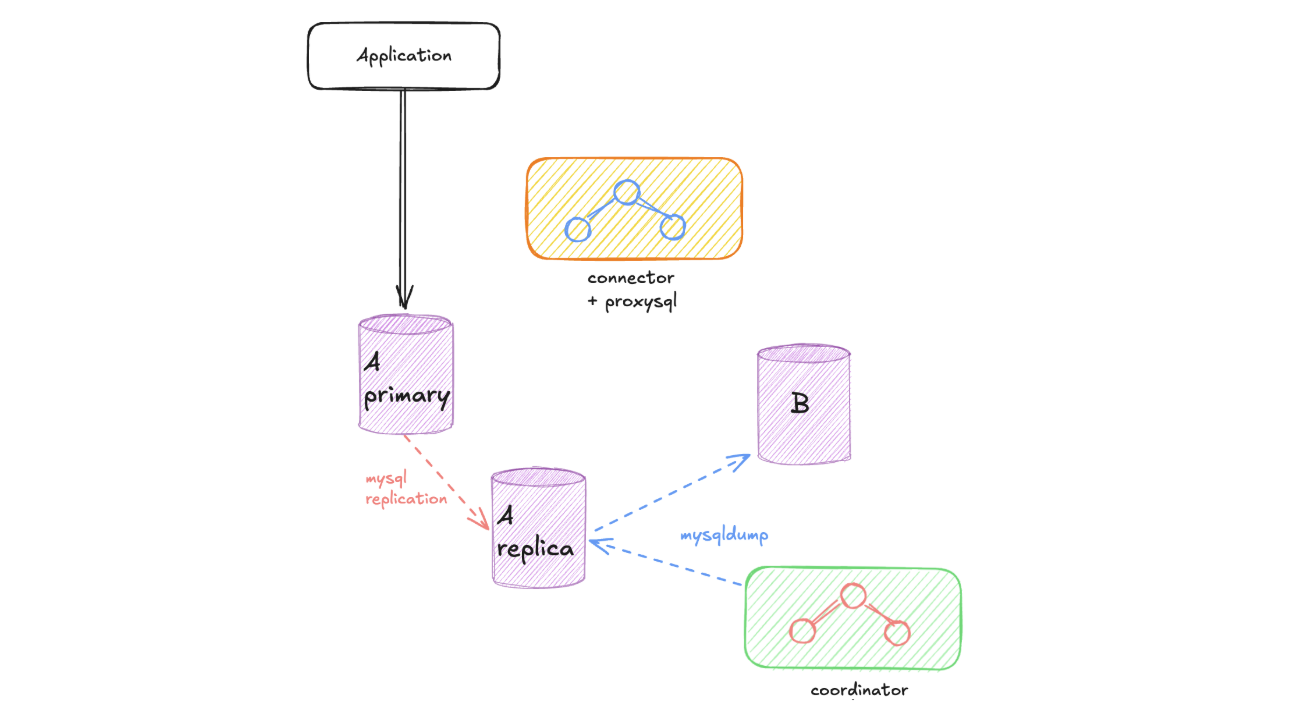
Execute Mysqldump: We perform a mysqldump operation, transferring all data from the read replica to the new instance. During this process, both the read replica and the new instance are isolated from production traffic, which continues to flow to the original instance.
Snapshot Approach
For larger databases where mysqldump would take an impractical amount of time, we use the snapshot approach:
Create New Instance From Snapshot: We create the new instance directly from a snapshot of the old instance. This approach is significantly faster for large datasets as it leverages AWS’s underlying storage technology.
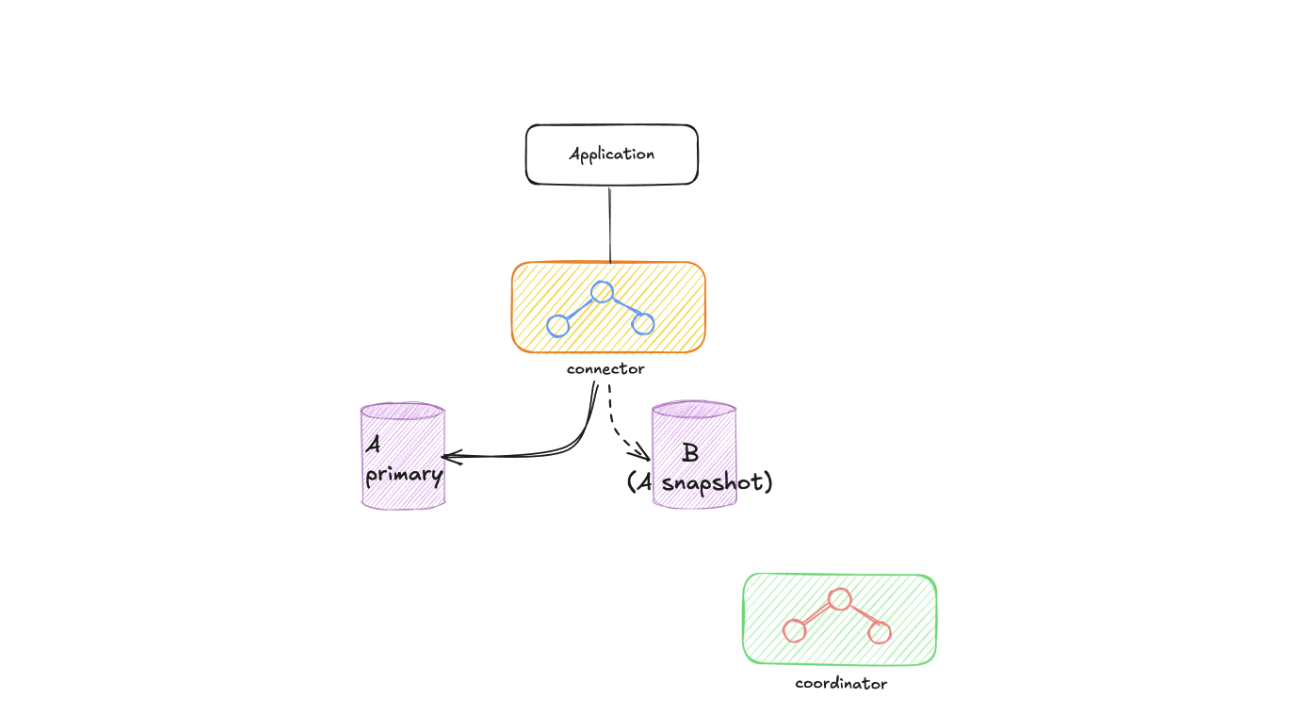
Important Limitation: The snapshot approach requires
GTID_MODEto be enabled on both old and new instances. Without GTID (Global Transaction Identifier), the new instance cannot determine the correct starting point for replication, making this approach unfeasible.
Final Sync Configuration
Regardless of the approach used, the final step involves establishing replication between the old and new instances:
Configure Master-Slave Replication: The new instance is configured as a slave of the original instance. For setups without GTID enabled (only possible with the mysqldump approach), the coordinator retrieves the MasterLogFile and ReadMasterLogPos from the read replica to configure replication accurately.
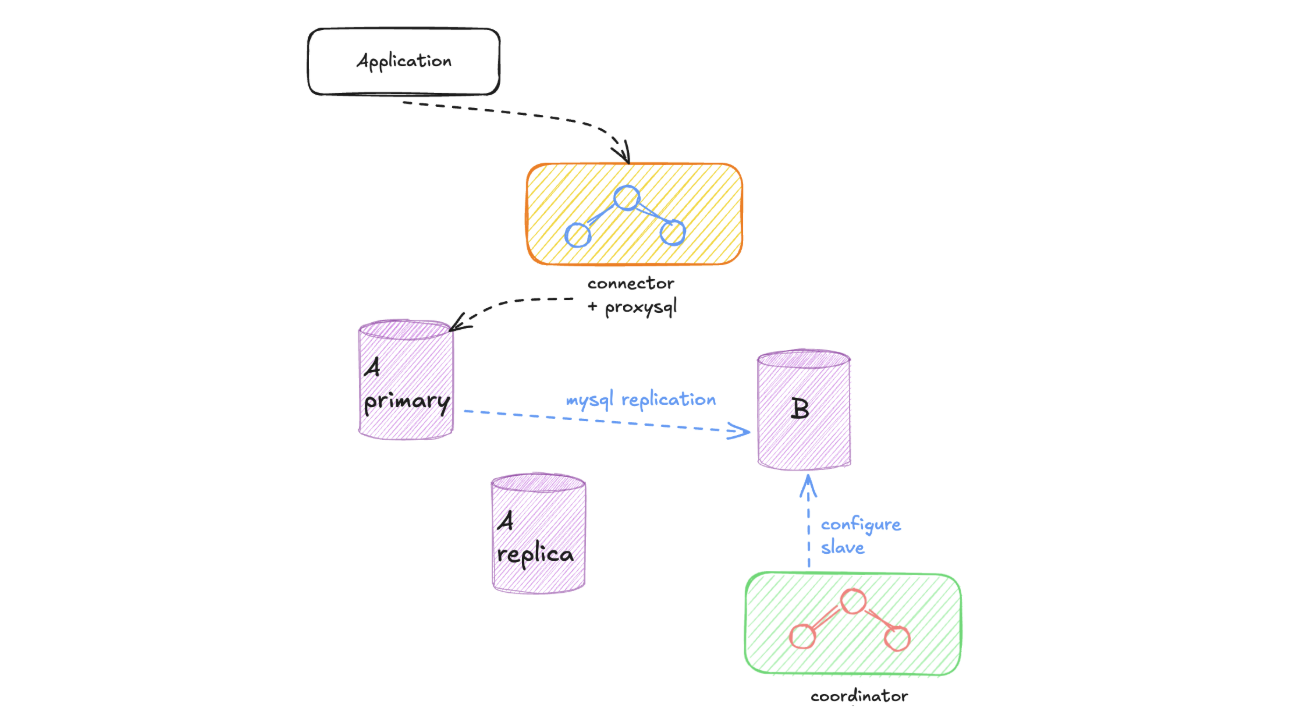
Monitor Replication Lag: We continuously monitor the replication lag between the old and new instances. Once the coordinator verifies that the replication lag is zero, the sync phase is considered complete, and both instances are perfectly synchronized.
This synchronization ensures that when we eventually switch traffic, no data will be lost, and the new instance will be an exact replica of the old one.
Refer to the following flow diagram for the sync process of the mysqldump approach:
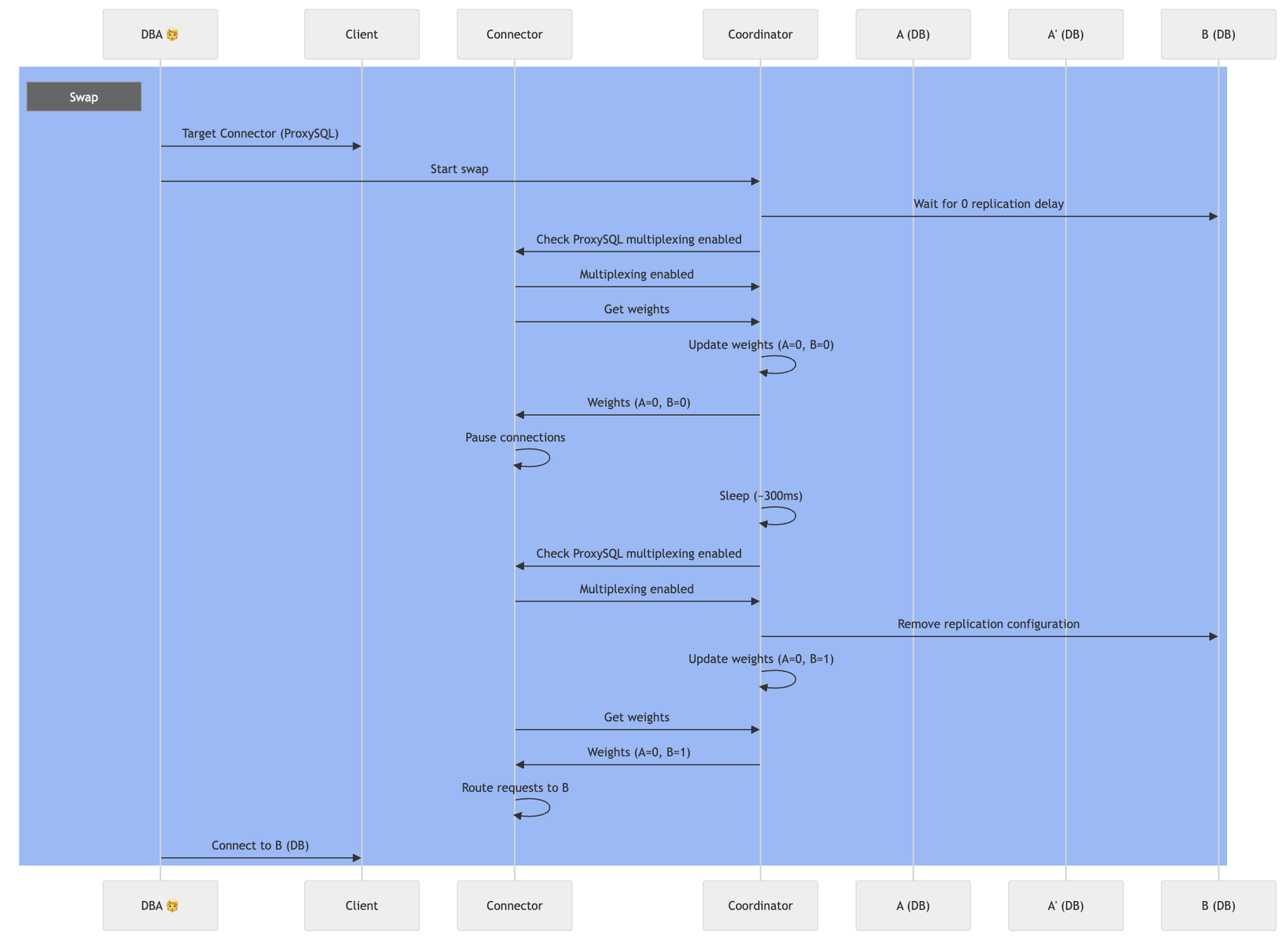
The swap phase is the most critical part of our zero-downtime migration process. With both instances perfectly synchronized, we now need to seamlessly redirect all database traffic from the old instance to the new one. This process requires precise coordination and timing to ensure no data loss or service interruption.
ProxySQL Connection: We route all traffic through ProxySQL (Connector) to the old instance. We request teams to modify their service client’s in order to point to the ProxySQL. From the service perspective, nothing changes, but this setup gives us complete control over traffic routing as the migration proceeds.
Traffic Suspension: The coordinator temporarily sets the configuration to stop all traffic routing. The connector, which continuously polls this configuration, immediately updates ProxySQL to set all database weights to 0. This creates a brief period (typically a few milliseconds) where no new traffic is routed to either instance.
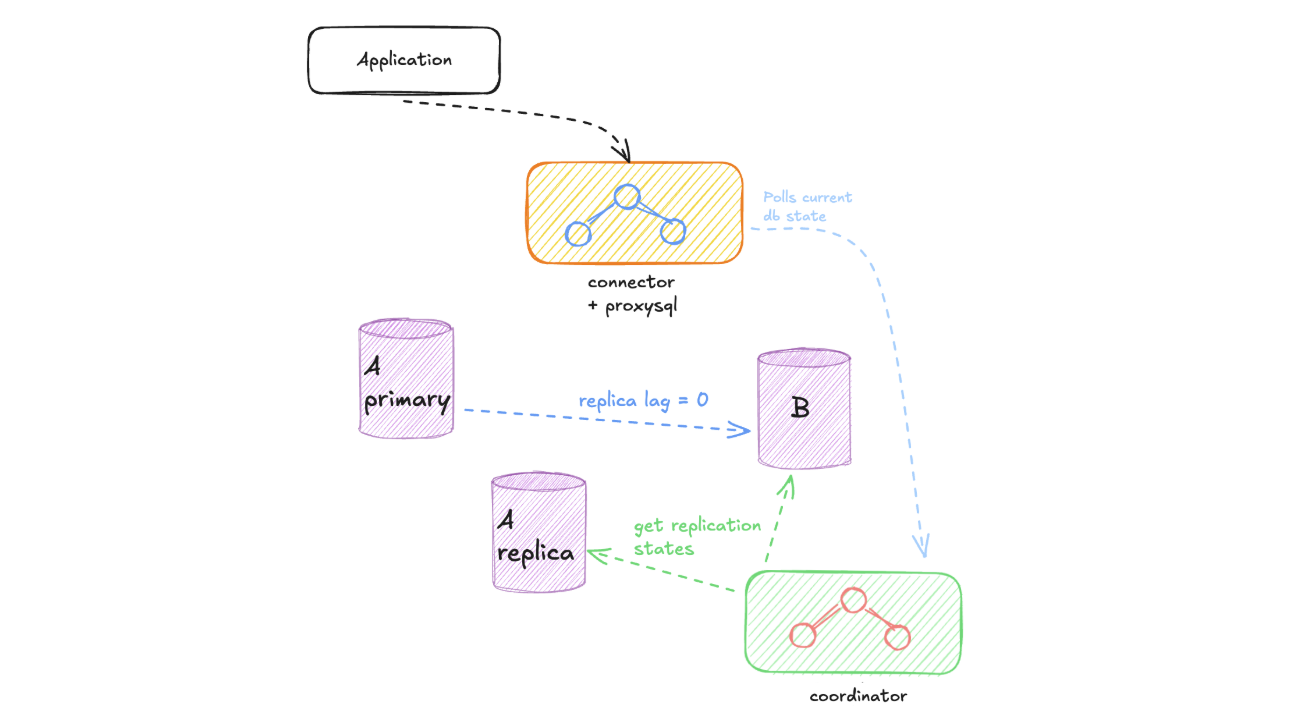
Important: This traffic suspension does not constitute downtime from the application’s perspective. ProxySQL queues incoming connections during this brief period, resulting in a slight latency increase rather than connection failures.
Route to New Instance: The coordinator updates the configuration to direct all traffic to the new instance. The connector detects this change and configures ProxySQL to route 100% of database traffic to the new instance, setting its weight to 1 while keeping the old instance weight at zero.
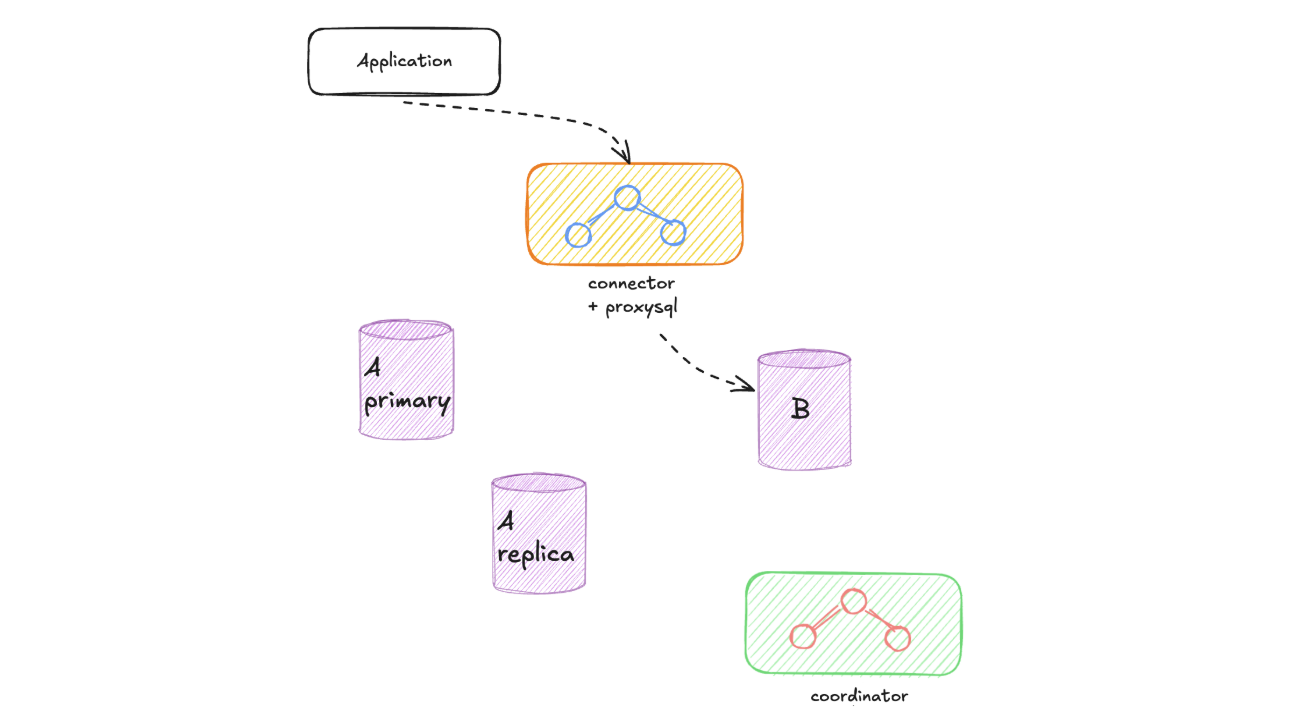
WARNING: The swap process requires careful handling of existing ProxySQL connections. Active transactions, table locks, or long-running queries may prevent some connections from being immediately redirected to the new instance. These “sticky” connections could continue executing commands on the old instance even after replication has stopped, potentially causing data loss.
To mitigate this risk, we verify that all connections have multiplexing enabled before doing the switch.
For more details on this behavior, refer to the ProxySQL multiplexing documentation.
The entire swap process typically completes within a few hundred milliseconds, during which applications experience only a slight increase in database connection latency rather than any actual downtime. This approach allows us to achieve true zero-downtime database migrations while maintaining complete data consistency.
Here is a complete flow diagram of the swap process:
While there are several alternatives available for database migrations, we sought a solution that minimizes downtime, avoids vendor lock-in, and provides the flexibility to migrate between instances across different cloud providers or database types (e.g. RDS vs Aurora). The combination of ProxySQL and a bit of custom code allows us to achieve this.
The challenges of database migrations are far from over. We aim to empower product teams to upgrade their MySQL databases independently; however, that is a story for the future.

Senior SRE